

Introduction
Threat actors increasingly operate across national boundaries, but information-operation detection rarely extends beyond single-language analysis, leaving blind spots in multilingual and visual domains. This focus on textual narratives neglects the critical role visuals play in spreading influence. Images carry powerful messages independent of language and can swiftly move across borders, enhancing narratives, shaping public perception, and often evading traditional detection methods.
To address this gap, a new automated reverse image detection feature has been integrated into the Alliance for Securing Democracy’s Information Laundromat. By automating the detection and aggregation of identical or near-identical images across the web, this feature allows researchers and policymakers to quickly trace how visual narratives are propagated through complex networks.
This report demonstrates the utility and effectiveness of reverse image detection at scale and reveals otherwise hidden connections between state-sponsored outlets and ostensibly independent or localized news sites. These findings demonstrate the utility and effectiveness of this approach, including identifying dissemination networks and mapping content-laundering activities that span multiple languages and regions.
Methodology
ASD first created a sample of 239 images from Sputnik’s Mediabank, an online repository of photographs and graphics maintained by Sputnik, the Russian government’s international news agency, because these images are provably associated with Russian state media. We selected four interrelated search terms—“Angara A–5”, “Luna 25”, “T80”, and “Igla”—to retrieve images that span Russian space, technology, and defense domains: a heavy-lift rocket, a failed lunar probe, a main battle tank, and a man portable air defense system.
Each image was then submitted to the Information Laundromat’s new “Image Similarity Search”, which interfaces with Google and Yandex’s reverse image searches. This exercise returns two sets of results:
- From Google’s exact match results, ASD received a list of URLs in which “exact matches” of a given image were found. The overwhelming majority of “exact” matches are accurate, but non-exact matches also appear.
- On Yandex and Google’s non-exact image matches, ASD compared the source and potential matching images using perceptual hashing, a process that generates a fingerprint for a given image and compares it to other fingerprints to find duplicates and visually similar images. Using this automated approach, the tool retrieved candidate pages that had either the same image file or a very close (>80%) match.
All the websites identified as hosting a target image (either exact or near matches) were compiled into a list. The results were first aggregated by domain name, counting the unique pages these images were found on and then sorting and ranking them. Rankings higher than 10 are approximate due to single outlets using multiple domain names—as is the case with much of Russian state media (for example, sputnik-georgia[.]com and sputnik-georgia[.]ru). We then conducted a similar secondary aggregation by their top-level domain (TLD). Examples include .ru, .com, and .vn. These two aggregates provide a high-level view of which countries and global domains are most prevalent in reusing Sputnik’s images.
Investigators then manually reviewed and annotated each of the 100 most frequently occurring domains (as well as a smattering of other domains that appear linked to the Russian state). They categorized each entry as: Russian state media; captured outlets (nominally independent outlets effectively controlled or influenced by the Russian state); Sputnik network (Sputnik’s regional outlets or affiliates); international platforms (generally social media or non-news sites); regional news outlets (with particular attention to those in Africa, Central Asia, and Eastern Europe); or specialized or technology-focused outlets. This classification enables analysis not just by geography (via TLD) but by type of outlet or its role in the information ecosystem.
Replicability, Limitations, and Suggestions for Further Analysis
This methodology does have limits, however, as perceptual hashing and search engine searches have trouble detecting and accounting for certain image transformations, such as “deep frying”—applying dozens of filters until an image appears grainy and washed out—or other, less radical color and position alterations. Such image alterations are not (yet) typically used by threat actors. Unfortunately, similar analyses are at the mercy of search engines’ indexing and near-duplicate image detection mechanisms, making replicability a challenge at best.
Image-reuse analysis also shows significant promise in tracking the spread of images across platforms. By combining datapoints like post timestamps and the community or community of origin, one could, for example, trace a meme as it passes through fringe communities and into the mainstream. In any case, the choice of sample for image-reuse analysis is critical. While this analysis focused on images from a known, single point of origin, the reverse—attempting to determine the source of a diverse set of images—is equally valid, as is clustering visually similar images such as memes and combining them with time-series analysis to understand where, when, and how visual information flows through the internet.
Results and Analysis
Top-Level Domains (TLD)
While the top-level domain is not typically indicative of a relationship between a source (in this case, Sputnik Media Bank) and a target, it can uncover broad trends in international influence. Table 1 shows nearly 2,405 uses across 1,900 unique domains that reused Sputnik imagery on Russia’s .ru domains, serving as a clear indicator of domestic propagation and aligning with expectations for state-originated content dissemination within Russia.
Beyond Russia, significant volumes of Sputnik images found on top-level domains such as .vn (Vietnam, 144 uses across 138 domains), .rs (Serbia, 128 uses across 109 domains), .cn (China, 96 uses across 89 occurrences), and .ir (Iran, 92 uses across 76 domains) suggest notable Russian media influence or at least strong receptivity to Russian-origin content within these national media ecosystems. Similarly, high reuse rates on domains in Belarus (.by, 68 uses across 53 domains), Uzbekistan (.uz, 41 uses across 41 domains), Kazakhstan (.kz, 50 uses across 40 domains), and countries in Central and Eastern Europea (.ro for Romania, .pl for Poland, .sk for Slovakia, and .cz for Czechia, each with around 40-50 domains) reflect historical ties, linguistic accessibility, or deliberate influence targeting by Russian media.
Conversely, the relatively low reuse of images on domains registered in large Western European countries (.fr, .de, .uk), especially in compassion to their populations, and nearly absent reuse on domains associated with other Western-aligned countries (e.g. .ca, .au) suggests a lack of receptivity to Sputnik and other Russian state-media outlets in those countries.

Figure 1: Top Level Domains with >15 occurrences by Volume of Domains and Unique URLs.
Analyzing the distribution of reused images by national top-level domains can reasonably be viewed as a proxy for the relative strength and reach of Russian state-media influence, particularly highlighting regions susceptible to or being targeted by Russian-origin visual narratives. However, this analysis is inherently macro-level, as there are few restrictions on who can register for a given TLD and non-geographic TLDs (.com, .net, .name, etc.) remain overwhelmingly popular. Therefore, manual- and tool-assisted categorization of individual domains is necessary for further analysis.
Mapping Russia’s Domestic Landscape
Much as examining TLDs was useful in exploring Russia’s international media influence, the frequency of use of the selected Sputnik Media Bank images provides a mechanism for understanding the influence of the state on domestic Russian media outlets. Indeed, most of the image reuse was found on websites directly tied to the Russian state-media apparatus, such as RIA Novosti, TASS, or RT, or on outlets that can be considered “captured” by the Russian state, a term that suggests a loss of editorial autonomy due to state ownership, coercion, or legal and financial pressures. For example, Channel One Russia, a public broadcaster, became captured when the Kremlin acquired a majority stake, appointed pro-government executives, and enforced editorial directives to promote state-approved narratives.
On overt state media, the consistent reuse of the same images underscores a coordinated messaging strategy: state media sharing assets to maintain narrative consistency. RIA Novosti (ria.ru) and Rossiyskaya Gazeta (rg.ru), two domestic Russian state-media entities, topped the rankings with 269 and 253 matches, respectively. These figures highlight the direct role that state-run media plays in disseminating the official visual narratives—at least in the technology and defense sectors—across Russia. Meanwhile, the extensive reuse of state-origin images by nominally “independent” outlets—Lenta.ru (210 instances, third-most frequent), Gazeta.ru (108 instances, fifth-most frequent), Izvestia (99 instances, seventh-most frequent), and Argumenty i Fakty (73 instances, ninth-most frequent) suggests an editorial reliance on materials produced by Russian state media and merits closer scrutiny. (The city of Moscow owns Argumenty i Fakty, so it exists in a state-controlled gray area). Similarly, Appendix 1 shows several as-yet uncategorized Russian domestic media outlets, like ampravda[.]ru and sdelanounas[.]ru, that show similar levels of image reuse as state-owned, regionally focused outlets like ukraina[.]ru. Given the high level of adoption by captured and state-owned media, other purportedly independent media outlets with high levels of image reuse merit re-examination.
Image-reuse analysis is similarly useful for mapping Sputnik properties and can provide a stand-in for their relative popularity, or at least, frequency appearing on search engines. Thirty-seven fully qualified Sputnik domain names (FQDNs) were observed across 753 results, though many were subdomains of sputniknews[.]ru. The breadth and depth of this network demonstrates the efficacy of image reuse analysis in network identification, as this method identified the majority of known Sputnik sites.
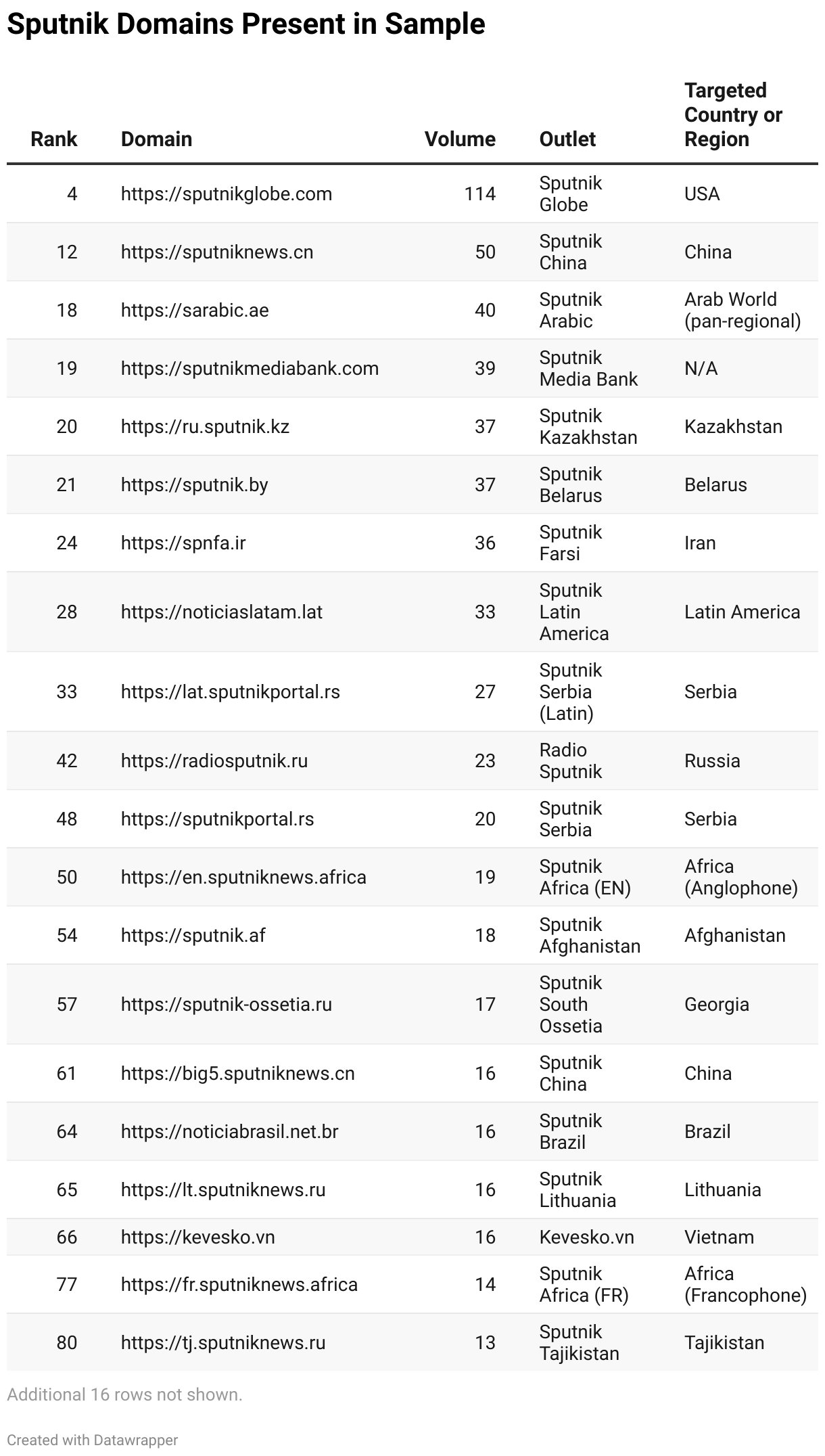
Figure 2: Sputnik URLs detected in the dataset, including URL, rank, volume, and country of focus.
Overall, the heavy domestic reuse of Sputnik Media Bank images across overt state-controlled and captured media suggests possible domestic coordination in narrative management. The magnitude and consistency of image reuse demonstrates its worth as a proxy for evaluating the relative influence and pervasiveness of Russian state media domestically, even demonstrating its usefulness as a network-identification tool.
Reposters and Mirrors
Image-reuse analysis also provides a language-neutral system for detecting information laundering, especially candidates that might be missed using other methods. However, this approach requires significantly more manual verification than automatable text comparison—uncovering serial launderers often means looking past the highest-volume users of those images, as there are many legitimate uses of those images. Still, in our sample, image-reuse analysis was successful in detecting several previously unknown reposters. It proved particularly successful at identifying traditionally under-researched languages and regions where Russia has key strategic interests.
For example, Africa-focused outlet Africa-Press.net was the ninth-most frequently found domain in our sample, with 69 image reuses, outpacing many Russian state media outlets. Africa Press appears to be a mass, multisource aggregator that groups news articles first by language, then by nation, rather than a single-source reposter. All instances of laundering found on the site were in English and sourced from Sputnik English, such as a Sputnik article on the Angara A-5 rocket launch that was reprinted for the Namibia and Sierra Leone portals.
Highlighting the language-neutral benefits of image-reuse analysis, our findings also revealed significant information-laundering levels in Arabic, including two Yemeni outlets, Sahafa 24 and Al-Minasa. Sahafa 24 was our seventeenth-most observed domain, edging out Sputnik Arabic itself. It is another aggregator, operating several sites under similar aliases and claiming to be the “the most visited [site] in Yemen.” It appears to copy its articles, and thus images, directly from RT Arabic. Al-Minasa, by contrast, literally embeds Sputnik Arabic into their website. A third Arabic site, Doha-based Marsal Qatar, also laundered its articles and images from Sputnik.
Image-reuse analysis provides more leads than can reasonably be investigated, especially among lower-volume matches. Even so, these are often the most fruitful leads. For example, Africa-China Press Centre (AfricaChinaPressCentre[.]org), which had only a single (100%) image match in our sample, was sourced from a reprint of a Xinhua article, one of up to 2000 reposted articles from Chinese sate-media outlet Xinhua on the site. Similarly, in name and effect, Africa Presse (africapresse[.]com, no apparent relation to the aforementioned Africa Press), a Francophone publication, appeared twice in our sample, once with a copy of a Sputnik article and once with an original piece. However, a brief site search reveals more than 100 articles that originated from Sputnik.

Figure 3: A screenshot of Africa-Press[.]net showing its multilingual support.
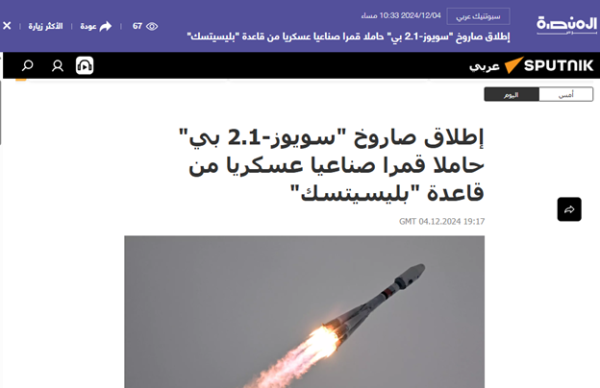
Figure 4: A screenshot of an Al-Minasa article that embeds the equivalent article from Sputnik inside of it.


Figures 5 and 6: Screenshots of Africa-China Press Centre and Xinhua, showing a laundered article.
Merely three image reuses were all that was necessary to uncover a small network of Middle East-focused news sites reposting RT in English. Each site was styled by the relevant country, and the network is run by a company called Mobilepasse. Four of their 26 “apps”, mostly simply websites, include articles from RT: qatarnewsapp[.]com, uaenewsapp[.]com, bahrainnewsapp[.]com, and lebanonnewsapp[.]com. The impact of these sites may be limited. They claim hundreds of thousands of downloads, but all their apps appear to have been removed from Google and Apple’s app stores.


Figures 7 and 8: A screenshot from lebanonnewsapp[.]com showing content laundering from RT, and another screenshot from Mobilepasse’s homepage claiming over 750,000 app downloads, respectively.
This pattern appears to extend to nearly any language with a Sputnik or RT outlet serving it. For example, Serbian-language portal CentralNews[.]live regularly reposts Sputnik Serbia, including two identical articles on the Luna-25 crash, first from Sputnik and then from Central News.
Still, given the number of launderers found through spot-checks alone, it is likely that additional Russian state-media launderers abound among the remaining ~2000 domains. Image reuse requires significantly more manual verification of its leads, but its language-neutral nature allows for greater variety among those leads, potentially heading off information operations that target vulnerable populations.
Conclusion
This research demonstrates that automated reverse image detection at scale provides a language-neutral methodology for uncovering information laundering and visual influence. Across multiple platforms and languages, ASD successfully mapped the domestic and international dissemination networks of Russian state-sponsored visuals originating from Sputnik Media Bank.
These findings reveal a distinct bifurcation in these images’ reuse patterns. Within Russia, state-controlled and captured media outlets exhibit high rates of image reuse, underscoring their closely coordinated media environment. Internationally, targeted image reuse aligns strategically with geopolitical interests, notably in regions historically receptive to or actively targeted by Russian influence such as Eastern Europe, Central Asia, Africa, and parts of Asia.
Despite inherent methodological limitations—such as indexing biases and image transformations—the reverse-image-detection method significantly enhances analysts’ ability to detect and analyze information operations that may otherwise evade traditional textual analysis. Additionally, our exploration revealed previously unidentified or under-examined information-laundering networks, highlighting the effectiveness of this approach in surfacing operations in less commonly studied languages and regions. This expands the potential for timely intervention and deeper understanding of transnational influence strategies.
The integration of reverse image detection tools ultimately represents a critical advancement in combating visual information laundering by enabling researchers and policymakers to better grasp the scale, tactics, and nuances of influence campaigns.
The views expressed in GMF publications and commentary are the views of the author alone.


