


The Artikel 38 Dashboard, hosted by the Alliance for Securing Democracy, monitors Russian influence operations on Twitter that target German-language audiences. The following document explains exactly what the dashboard shows and the methodology used to construct it.
Dieses Dashboard beobachtet russische Einflussoperationen im sozialen Netzwerk Twitter, die an deutschsprachige Zielgruppen gerichtet sind.
Einflussoperationen, ob aus Russland oder anderen Staaten, wollen die Sichtbarkeit und Wahrnehmung bestimmter Themen verändern. Sie tun das, indem sie die Reichweite bestimmter Inhalten verstärken – beispielsweise durch das Teilen von Hashtags und URLs, die auf längere Artikel und Videos verlinken.
Die Urheber der Einflusskampagne erstellen dabei nur einen Teil der verbreiteten Inhalte selbst. Viele der in diesem Dashboard gezeigten Aktivitäten stammen ursprünglich von dritten Parteien und werden dann von Accounts vervielfältigt, die mit den russischen Einflussoperationen verbunden sind.
Die Urheber der Inhalte haben nicht zwangsläufig direkte Verbindungen nach Russland, aber ihre Inhalte passen zu den Themen, deren Reichweite diese Netzwerke verstärken wollen. Die Themen drehen sich oft, aber nicht ausschließlich, um rechtsradikale Bewegungen und Einwanderungsfeindlichkeit.
ZUSAMMENFASSUNG
Um eine Liste von zu verfolgenden Twitter-Konten zu erstellen, haben wir die Followers von @de_sputnik, dem deutschsprachigen Twitter-Account von Sputnik News, untersucht.
Während Sputnik ein unverhohlenes Mittel russischer Einflussnahme darstellt und daher eine wichtige Rolle in den Beeinflussungskampagnen spielt, sind natürlich nicht alle Sputnik-Follower auf Twitter direkt in solche Kampagnen involviert. Wir haben daher Kriterien und Metriken aufgestellt, mit deren Hilfe die wichtigsten Nutzer identifiziert werden können. Das Dashboard zeigt den Output von:
- Nutzern, die Inhalte twittern, mit denen die Follower von @de_sputnik interagieren,
- Nutzern, die aktiv mit diesen Inhalten interagieren, und
- Nutzern, die künstlich die Reichweite der Inhalte innerhalb des Netzwerks erhöhen.
Die Untersuchung wurde im Juli 2017 vorgenommen und spiegelt die Aktivität des Netzwerks in diesem Zeitraum wider. Die gleiche Untersuchung zu einem anderen Zeitraum käme zu vergleichbaren, aber im Detail abweichenden Ergebnissen.
Wir haben die Follower von @de_sputnik für die Untersuchung in drei Gruppen unterteilt:
- Die 500 einflussreichsten Accounts: Dabei handelt es sich um die Konten, deren Beiträge die meisten Interaktionen (Retweets und Antworten) von anderen @de_sputnik-Followern erhalten haben.
- Die 500 empfänglichsten Accounts für Einflussnahme: Dies sind die Accounts, die am häufigsten (durch Retweets und Antworten) mit denen von den einflussreichsten Accounts geteilten Inhalten interagieren.
- Die 500 interaktivsten Accounts innerhalb des Netzwerks: Dabei handelt es sich um die Accounts, die am häufigsten mit anderen Followern von @de_sputnik interagieren – im Verhältnis zu Interaktionen mit Nutzern, die keine @de_sputnik-Follower sind.
Die von uns verwendeten Messverfahren und Metriken werden weiter unten detailliert beschrieben. Die drei Gruppen überlappen zu einem gewissen Grad; insgesamt haben wir 1.307 Accounts erfasst, von denen 104 (acht Prozent) seit der Erfassung des Netzwerks im Juli 2017 gesperrt oder gelöscht wurden. Um maximale Relevanz zu erreichen, haben wir den Datensatz weiter gefiltert und Accounts von nicht primär deutschsprachigen Nutzern aussortiert. Die übrigen Accounts haben wir nach der Anzahl ihrer Follower sortiert und die 500 Accounts mit den wenigsten Followern ausgewählt, um unsere Analyse auf die weniger offensichtlichen Teilnehmer des Netzwerks zu konzentrieren.
Anschließend haben wir erneut auf die Gesamtzahl aller @de_sputnik-Follower zurückgegriffen und mutmaßliche Bot- und Troll-Accounts, die hauptsächlich der künstlichen Vervielfältigung anderer Accounts dienen, ausfindig gemacht. Für diesen Schritt haben wir folgende Accounts identifiziert:
- Accounts mit weniger als 5.000 Followern
- Accounts mit mehr als 100 Tweets pro Tag
- Accounts, deren letzten 200 Tweets zu mindestens 25 Prozent aus Retweets bestanden
Aus dieser Gruppe haben wir die bis dahin noch nicht enthaltenen Accounts zu dem Datensatz hinzugefügt, sodass der finale Datensatz aus insgesamt 600 Accounts besteht.
Dieser finale Datensatz ist eine repräsentative Stichprobe von Accounts, die grundsätzlich die Positionen des Ursprungsaccounts @de_sputnik teilen. Dazu zählen durch den Ursprungsaccount messbar beeinflusste Twitter-Konten, aber auch Accounts, die effektiv die Follower des Ursprungsaccounts beeinflussen sowie solche Accounts, die die Inhalte der Accounts ersten beiden Gruppen weiterverbreiten.
Da wir entschieden haben, im Dashboard auch Aktivitäten von Bots abzubilden, kann sich vereinzelt kommerzieller Spam in den Datensatz einschleichen. Wir haben versucht, solche Accounts möglichst aus dem Datensatz zu entfernen. Dies geschieht durch die Identifizierung von Twitter-Konten, die Dopplungen und Wiederholungen versenden und, in begrenztem Rahmen, auch durch händische Prüfung.
VERWENDETE METRIKEN
Die folgende Diskussion der Verfahren zur Berechnung von Einfluss, Empfänglichkeit und In-Groupness wurde in Teilen aus den folgenden Studien, die sich im Detail mit den Metriken und ihrer Performanz befassen, adaptiert:
- Who Matters Online: Measuring influence, Evaluating Content and Countering Violent Extremism in Online Social Networks, J.M. Berger und Bill Strathearn, International Centre for the Study of Radicalisation (März 2013)
- The ISIS Twitter census: Defining and describing the population of ISIS supporters on Twitter, J.M. Berger und Jonathon Morgan, The Brookings Institution (März 2015)
Messung von Einfluss und Empfänglichkeit
Einfluss ist die Tendenz eines Nutzers, andere Nutzer zu einer messbaren Reaktion (wie zum Beispiel Retweets oder Antworten) zu inspirieren. Die Kehrseite von Einfluss ist die Empfänglichkeit für ebendiesen: Empfänglichkeit ist die Tendenz eines Nutzers, in einer messbaren Weise auf einen anderen Nutzer zu reagieren.
Einfluss und Empfänglichkeit wurden für jeden Account anhand der neuesten 200 Tweets berechnet. Dabei wurde eine gewichtete Formel angewendet, die die Anzahl der Retweets, direkte Antworten auf Tweets, sonstige Nennungen des Accounts und die Anzahl der Follower innerhalb des Netzwerks einbezieht – und diese Daten in Bezug zur Gesamtzahl der Tweets setzt. Diese Gewichtung verhindert die Bevorteilung von Accounts, die in sehr großen Mengen twittern.
Wie die Gewichtung genau funktioniert, ist in Appendix B von „Who Matters Online“ – eine Studie, die Netzwerke weißer U.S.-Nationalisten auf Twitter untersucht – beschrieben. Im Vergleich zu den Formeln der „Who Matters Online“-Studie wurde für das Dashboard eine Modifikation vorgenommen: Während in der ursprünglichen Studie die verschiedenen Arten von Non-Reply-Nennungen (d.h. Nennungen von Accounts außerhalb von Retweets und direkten Antworten auf Tweets) unterschiedlich gewichtet wurden, wurden sie hier in einer Kategorie zusammengefasst. Dies geschah nachdem eine Prüfung ergeben hatte, dass die Unterscheidung mehrerer Non-Reply-Kategorien einen zu vernachlässigenden Effekt auf die Ergebnisse hatte.
Die angesprochenen Formeln und Metriken werden auf mittelgroße Datensätze, deren Zusammensetzung auf einem oder mehreren Ursprungsaccounts basiert, angewendet. Die aus der Analyse resultierenden Zahlen messen den Einfluss und die Empfänglichkeit für Einflussnahme von Accounts innerhalb des gesamten Netzwerks. Die von den Metriken gelieferten Ergebnisse wurden codiert und analysiert, um die Performanz der Berechnungsverfahren zu evaluieren. Es zeigt sich, dass die Accounts mit den höchsten Werten in ihrer Orientierung durchgängig den Ursprungsaccounts ähneln. Durch die Hinzunahme der Faktoren Einfluss und Empfänglichkeit entsteht eine Metrik zur Erfassung von Interaktivität, mit der die Relevanz der Accounts noch besser bestimmt werden kann. Die zuvor auf Basis dieser Metriken veröffentlichten Ergebnisse finden sich in den folgenden Abbildungen „Who Matters Online“.
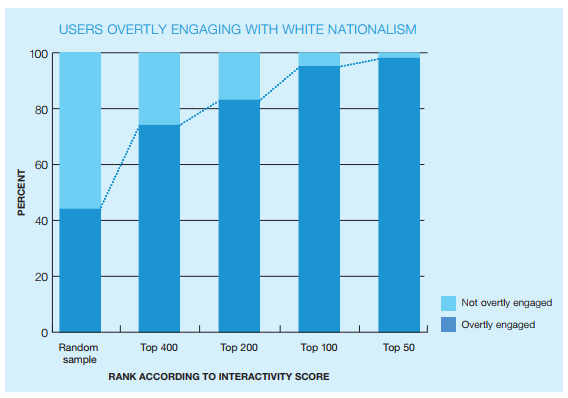
Figure 1: Accuracy of combined influence and exposure metric at surfacing accounts related to seed accounts. Source: Who Matters Online (ICSR 2013).
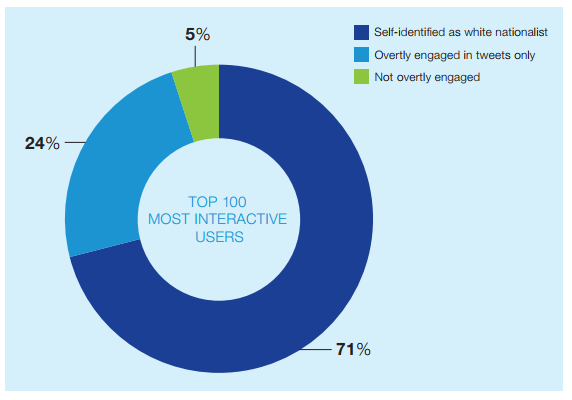
Figure 2: Accuracy of combined influence and exposure metric at surfacing accounts related to seed accounts. Source: Who Matters Online (ICSR 2013).
Berechnung der In-Groupness
Nachdem den für dieses Dashboard analysierten Accounts jeweils Zahlenwerte für Einfluss und Empfänglichkeit zugeordnet wurden, wurde anschließend die sogenannte In-Groupness jedes Accounts berechnet. Wie die bisherige Forschung zu diesem Thema zeigt, können die Messergebnisse bei der Untersuchung großer Netzwerke, die auf ähnlichen Ursprungsaccounts beruhen, bereits weitgehend auf der Basis von netzwerkinternen Metriken nach Relevanz sortiert werden. Anders gesagt: Die Relevanz der Akteure eines Netzwerks, das auf einem einzelnen oder mehreren ähnlichen Ursprungsaccounts aufbaut, kann bereits anhand der Häufigkeit der direkten Interaktionen (darunter das Folgen, Retweeten und Antworten) zwischen den Netzwerkmitgliedern – im Verhältnis zur Häufigkeit der Interaktionen mit Personen außerhalb des Netzwerks – in ein Ranking gebracht werden. Dieser Ansatz hat sich als präziser erwiesen als die alleinige Messung von Einfluss und Empfänglichkeit.
Die hier ebenfalls verwendete Methodologie und Metrik dieses Ansatzes wurde detailliert in „The ISIS Twitter Census“ beschrieben. Darin wurden für jeden Nutzer folgende Zahlen addiert:
- Anzahl der netzwerkinternen Freunde;
- Anzahl der Follower innerhalb des Netzwerks, aus Gründen der Gewichtung multipliziert mit dem Faktor Acht;
- Summe der netzwerkinternen Freunde aller Mitglieder der größten „Clique“, zu der der Nutzer innerhalb des Netzwerks gehört, multipliziert mit dem Faktor 16.
Die Summe dieser Zahlen wurde anschließend mit dem Quotienten aus der Anzahl der netzwerkinternen Follower des Nutzers, geteilt durch die Anzahl der externen Followers (Gesamtzahl der Followers des Nutzers minus die Zahl der netzwerkinternen Followers), multipliziert.
Die Ergebnisse waren extrem präzise (siehe untenstehende Abbildung), allerdings gestaltete sich die Analyse sehr zeitintensiv – hauptsächlich aufgrund von API-Beschränkungen bei der Analyse von Follower-Beziehungen auf Twitter. Wir haben eine mathematische Analyse an dem codierten Datensatz der „The ISIS Twitter Census“-Studie durchgeführt, um die Resultate auf schnellerem Wege replizieren zu können. Dieser Ansatz produzierte eine recht ähnliche Formel, die sich vor allem auf die netzwerkinternen Beziehungen konzentriert. Die schnellere Formel zeigte eine Genauigkeitsrate von 96 Prozent, verglichen zu 98,5 Prozent bei Verwendung der aufwendigeren Formel – was für die meisten Zwecke eine zufriedenstellende Annäherung darstellt.
Für das Dashboard haben wir die Ergebnisse wie schon oben beschrieben weiter gefiltert, um die Genauigkeit auf über 96 Prozent zu erhöhen. Außerdem haben wir eine kurze händische Analyse der identifizierten Accounts vorgenommen. Unserer Meinung nach sollte das Endergebnis dieses Monitorings vergleichbar sein mit der Genauigkeit der ursprünglichen IQI-Metrik bei der Identifizierung von Accounts, die hauptsächlich auf den Ursprungsaccount (in diesem Fall @de_sputnik) ausgerichtet sind – dazu zählen auch Konten, die Einfluss auf ähnliche Themen und weitere Nutzer nehmen, sowie Accounts, die die Inhalte der einflussreichsten Netzwerkteilnehmer aktiv weiterverbreiten.

Figure 3: Accuracy of IQI metric. Source: The ISIS Twitter Census
Verteilung der Ergebnisse
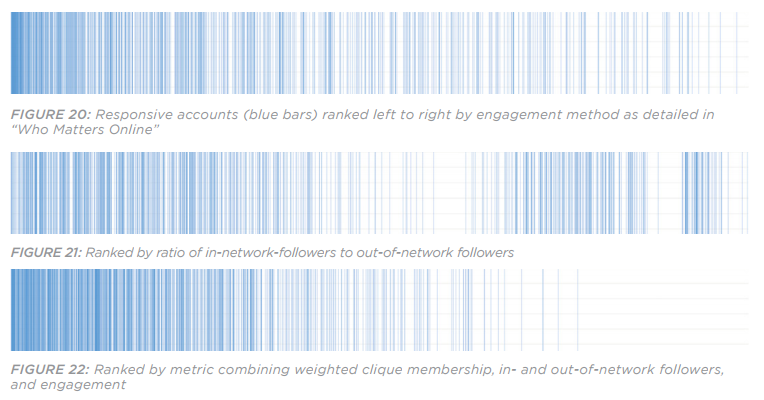
Figure 4: Distribution of responsive results using the combined Influence/Exposure metric (top) and the In-Groupness (bottom)
Die Genauigkeit der oben beschriebenen Metriken wurde anhand einer händisch codierten Stichprobe der Ergebnisse getestet. Wir haben die Accounts dieser Stichprobe gemäß verschiedener Bewertungsmechanismen sortiert, um die Metrik zu finden, mit der sich am präzisesten Accounts identifizieren lassen, die den Ursprungsaccounts inhaltlich möglichst ähnlich sind.
In dem obenstehenden Beispiel – basierend auf einem großen Netzwerk von Accounts, die bekannten ISIS-Anhängern auf Twitter gefolgt sind – stellen die blauen Balken Accounts dar, die ISIS offen unterstützten. Die weißen Balken symbolisieren Accounts, die keine offene Unterstützung zeigten. Die Darstellungen stammen aus „The ISIS Twitter Census“.
Wie die Abbildungen zeigen, sind die Metriken zur Erstellung von Rankings geeignet, aber sie identifizieren nicht alle relevanten Accounts in dem Netzwerk, und sie liefern keine hundertprozentig akkurate Liste der besonders relevanten Accounts mit den höchsten Werten in den einzelnen Kategorien.
Der Ansatz ist allerdings äußerst effektiv für die Auswahl repräsentativer Stichproben aus einem Netzwerk, das die inhaltliche Ausrichtung seines Ursprungsaccounts widerspiegelt. Aus diesem Grund behaupten wir nicht, dass die dem Dashboard zugrundeliegende Monitoring-Liste zu 100 Prozent akkurat ist. Vielmehr handelt es sich um eine sehr präzise und repräsentative Stichprobe relevanter Accounts.


