


The Artikel 38 Dashboard, hosted by the Alliance for Securing Democracy, monitors Russian influence operations on Twitter that target German-language audiences. The following document explains exactly what the dashboard shows and the methodology used to construct it.
Influence operations, Russian or otherwise, aim to raise the profile of certain themes and issues. They do this by amplifying content, including topics, hashtags, and URLs linking to longer stories and video.
The authors of the campaign create some of the content they amplify, but not all of it. Much of the activity featured in this dashboard is created by third parties, then amplified by accounts linked to Russian influence operations.
The authors of the content may or may not be directly linked to Russia, but their content reflects the themes that the network seeks to amplify. These themes are frequently, but not exclusively, focused on right-wing movements and anti-immigration extremism.
SUMMARY
To develop a list of Twitter accounts for monitoring, we analyzed followers of @de_sputnik, the German-language Twitter account for Sputnik News.
While Sputnik is an overt vehicle for Russian influence, and thus obviously relevant to influence campaigns, not all of its followers on Twitter are meaningfully involved in such campaigns. Therefore we applied metrics to the set to find the most relevant users. The resulting dashboard monitors the output of:
- users who tweet content that followers of @de_sputnik engage with,
- users who actively engage with that content, and
- users who artificially amplify content within the network.
The analysis was performed in July 2017 and reflects activity from that period. The same analysis carried out at a different time would produce similar but distinct results.
We analyzed the followers of @de_sputnik in three ways, identifying:
- The 500 most influential accounts: These are accounts that receive the highest number of interactions (retweets, replies) from people who follow @de_sputnik
- The 500 accounts most responsive to influence: These are accounts that most actively engage with the content promoted by the influential accounts (by sending retweets and replies).
- The 500 top accounts scored by in-groupness: These are accounts that most-often direct interactions to other followers of @de_sputnik, relative to interactions sent to non-followers.
The metrics we used are fully detailed below. The three sets overlapped somewhat, for a total of 1,307 accounts, of which 104 (8 percent) had been suspended since the network was collected in July 2017. We weeded this set for maximum relevance, including removing accounts that indicated German was not the user’s first language. We sorted the remainder by follower count and included the 500 accounts with the lowest number of followers, in order to focus the analysis on less obvious participants.
We then returned to the analysis of the follower set to identify likely bot and troll accounts that exist primarily to artificially amplify other accounts. To do this, we identified accounts with:
- Fewer than 5,000 followers
- More than 100 tweets per day
- With at least 25 percent of their last 200 tweets being retweets
We then sorted this set by in-groupness and included the accounts that were not already included in one of the previous sets for a final total of 600 accounts.
The resulting dataset is a representative sample of accounts that generally share the same orientation as the seed account, @de_sputnik, including accounts that are measurably influenced by the seed account, other accounts that are effective at influencing the followers of the seed account, and accounts that amplify members of the first two sets.
Because we chose to highlight some bot activity, some commercial spam may creep into the dataset. We have attempted to remove these accounts when possible, primarily by identifying accounts that send repetitive and duplicative content, but also through a limited manual review.
METRICS EMPLOYED
The following discussion of Influence, Exposure, and In-Groupness metrics is adapted in part from two sources that discuss both the metrics and their performance in detail:
- Who Matters Online: Measuring Influence, Evaluating Content and Countering Violent Extremism in Online Social Networks, J.M. Berger and Bill Strathearn, International Centre for the Study of Radicalisation (March 2013)
- The ISIS Twitter Census: Defining and Describing the Population of ISIS Supporters on Twitter, J.M. Berger and Jonathon Morgan, The Brookings Institution (March 2015)
Influence and Exposure Metrics
Influence is the tendency of a user to inspire a measurable reaction from other users (such as replies or retweets). Exposure is the flip side of influence, this is engagement, or the tendency of a user to respond to another user in a measurable way.
Influence and exposure were calculated based on the most recent 200 tweets from each account, using a weighted formula that scored accounts for retweets, at-replies, non-reply mentions, and number of in-network followers, factored for the volume of tweets. The volume of tweets metric was weighted to avoid unduly benefiting accounts that tweet at very high volumes.
The precise weighting is described in appendix B of “Who Matters Online,” which examined white nationalist networks on Twitter. One modification was made to the formulas in the original paper. The metric described therein weighted types of non-reply mentions differently, but these were subsequently consolidated as one category for non-reply mentions, after an assessment found that distinguishing the categories of non-reply mentions had a negligible effect on the results.
The metrics are applied to medium-sized datasets collected based on a “seed” account or accounts. The resulting scores measure influence and exposure to influence within the overall networks. The results produced by the metric were coded and assessed to evaluate the performance of the metrics. Top scoring accounts consistently prove similar in orientation to the seed account or accounts. Adding influence and exposure produced an interactivity metric that was even more effective at sorting for relevance. The earlier published results for this metric are shown in the charts below, taken from
“Who Matters Online.”
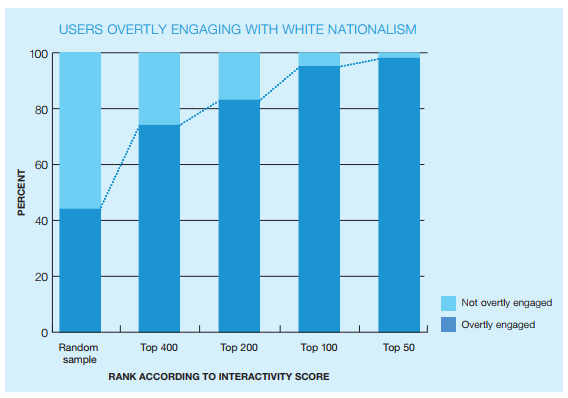
Figure 1: Accuracy of combined influence and exposure metric at surfacing accounts related to seed accounts. Source: Who Matters Online (ICSR 2013).
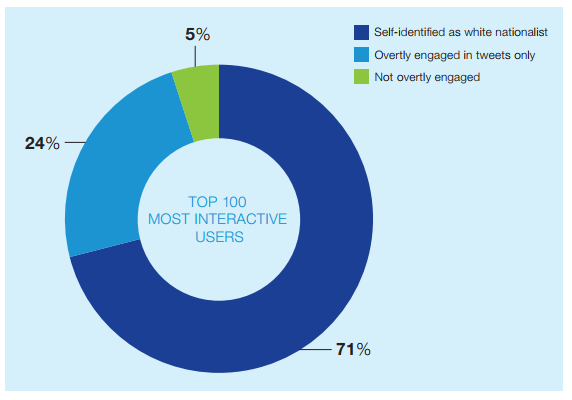
Figure 2: Accuracy of combined influence and exposure metric at surfacing accounts related to seed accounts. Source: Who Matters Online (ICSR 2013).
In-Groupness Metric
Once the accounts we analyzed for this dashboard were scored for Influence and Exposure, they were subsequently scored for in-groupness. Initial research on in-groupness demonstrated that measurements of a large network based on similar seeds could be sorted for relevance based on metrics largely focused on the internal network focus. In other words, a network based on a single seed or a collection of similar seeds could be sorted for relevance based on how frequently users directed interactions (including replies, retweets, and following) toward other members of the network, as opposed to the same actions directed outside the network. This approach has proven to be more accurate than measuring Influence and Exposure alone.
This metric and the methodology used was described in detail in “The ISIS Twitter Census.” The approach added the total number of each user’s:
- In-network friends;
- In-network followers multiplied by eight for weighting purposes;
- The sum of the in-network friends of all the users in the largest clique to which the user belonged, multiplied by 16.
The sum of these measurements was then multiplied by the ratio of the user’s followers within the network divided by the number of followers outside the network (total number of followers minus in-network followers).
The results were extremely accurate (see chart below), but the analysis was very time consuming, primarily due to Twitter API restrictions on analyzing follower relationships. We took the coded dataset and ran a mathematical analysis to replicate the results in a faster analysis. This produced a fairly similar formula mainly focused on in-network interactions. The faster formula had a top-tier accuracy rate of 96 percent, compared to 98.5 percent using the slow formula, which we assessed to be satisfactory for most purposes.
For the dashboard monitoring list, we weeded the results as described above to improve the accuracy above 96 percent and also performed a brief manual review of the accounts identified. We believe the final result for this monitoring set should be comparable to the performance of the original IQI metric in identifying accounts primarily aligned with the content of the seed account, in this case, @de_sputnik, including accounts that promote influence on similar themes and accounts that actively echo the content promoted by the top influencers.

Figure 3: Accuracy of IQI metric. Source: The ISIS Twitter Census
Scoring Distribution
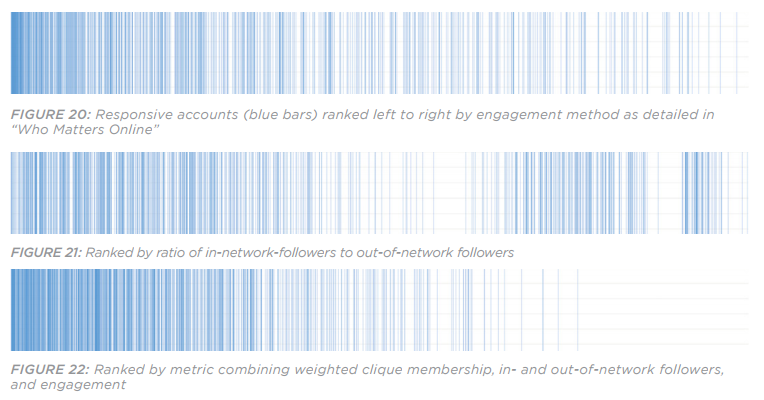
Figure 4: Distribution of responsive results using the combined Influence/Exposure metric (top) and the In-Groupness (bottom)
The accuracy of the metrics described above was determined by manually coding a random sample of results. We then ranked the accounts based on different scoring mechanisms to find the most accurate metric to identify accounts similar to the seed accounts.
In the example above, based on a large network of accounts that followed known ISIS supporters, the blue bars indicate an account that overtly supported ISIS, and the white bars represent accounts that did not overtly support ISIS. The graphs above are taken from “The ISIS Twitter Census.”
As the charts illustrate, the metrics are demonstrably effective at sorting, but they do not identify all relevant accounts in the network, and they do not provide for a 100 percent accurate list of relevant accounts in the top scoring positions.
The approach is very effective, however, at developing representative samples from a network that reflect the content orientation of the seed account or accounts. That is why we do not claim that the monitoring list is 100 percent accurate, but rather that is a highly accurate and representative sample of relevant accounts.


